文心大模子赋能生意智能助手的探索与实践

导读本文将共享文心大模子在构建生意智能助手中的探索与实践,重心叙述其在爱企查中晋升生意收益和用户体验的应用。文中将先容利用大模子代码生成能力,和常识图谱,优化数据库查询着力,并通过加入表结构和样例数据晋升代码生成准确率,还将先容怎么利用图形可视化进一步晋升数据分析着力。
主要包括以下五大部分:
1. 生意信息查询先容
2. 文心大模子构建生意智能助手的几种模式
3. 文心大模子赋能生意智能助手进阶
4. 生意智能助手的改日预计
5. 问答能力
共享嘉宾|叶汇龙 百度讨论院 资深工程师
裁剪整理|王红雨
内容校对|李瑶
出品社区|DataFun
01
生意信息查询先容
率先来先容一下生意信息查询的应用场景。
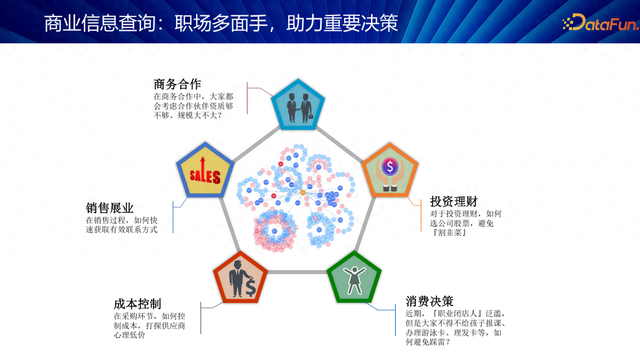
销售展业:快速获取目的企业的有用连络方式,加快业务激动。
资本适度:通过了解供应商的资本结构和热诚底价,利用博弈政策优化采购价钱,罢了资本从简。
奢华决策:“行状闭店东说念主”泛滥,如安在办理多样奢华卡时幸免踩雷。
投资愉快:怎么遴荐股票,幸免被“割韭菜”。
以上场景中,有些是当代生意决策的关节,有些则与咱们个东说念主生存息息有关。要惩处这些问题,有蓄意之一等于去查询这些企业的信息,其投资联系、供应链联系,这等于生意信息查询。
生意信息查询是一个职场多边手,大约助力咱们的一些蹙迫决策。
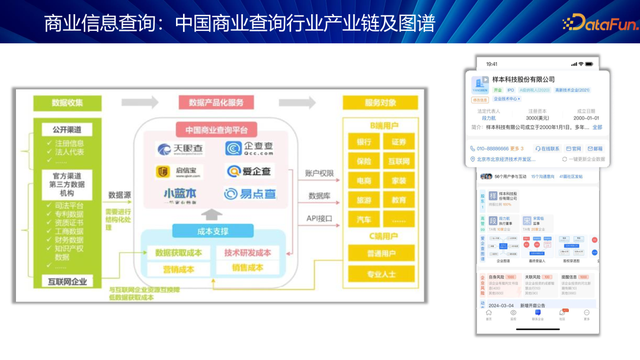
大部分生意信息查询处事,如天眼查、企查查、爱企查等,主要通过整合来自公开渠说念、第三方平台和官方记载的海量数据,为用户提供全面、精确的信息处事。这些平台网罗包括企业注册信息、财务数据、法律诉讼、行业动态等多元信息,将其家具化,以兴盛不同用户需求。
处事对象粗拙,既面向 B 端企业,匡助企业进行市集调研、竞争敌手分析、风险评估等,也惠及 C 端个东说念主用户,在奢华决策、投资愉快、行状辩论等方面提供数据复旧。以百度旗下爱企查为例,其效果权贵,为用户提供了高效、通俗的生意信息查询体验。通过这些平台,用户大约快速获取所需信息,作念出更理智的生意和生存决策。
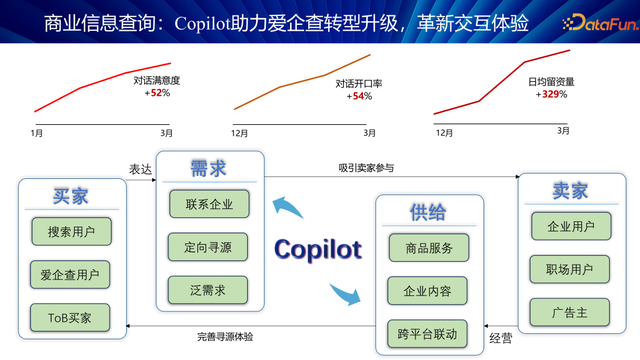
咱们在前年底开动利用 Copilot 来助力爱企查转型升级,改良交互体验,晋升生意着力。Copilot 的中枢功能在于精确匹配供需两边,既兴盛买家的采购需求,又确保卖家的优质供给,通过高效撮合,促进了两边的深度交流与并吞。
至本年 3 月,Copilot 系统展现出权贵收效,具体阐扬为:
对话惬意度晋升 52%:通过智能匹配,对话质料权贵提高,用户反馈愈加积极。
对话启齿率晋升 54%:系统精确保举,有用提高了两边疏通的针对性和着力。
日均留资量晋升 329%:这一生意辩论的大幅晋升,意味着系统大约权贵加多用户的活跃度和粘性,关于爱企查这么的通用平台而言,这意味着从免用度户到付用度户的滚动率得到了权贵晋升。
Copilot 通过优化匹配机制,不仅晋升了用户对话的惬意度和着力,还径直促进了企业的收益增长,增强了用户体验。这一效果讲授,Copilot 是企业数字化转型的有用器用。通过 Compiler,企业大约愈加精确地触达目的客户,提高滚动率,罢了生意目的的同期,也为用户创造更多价值。
02
文心大模子构建生意智能助手的几种模式
接下来先容咱们怎么利用文心大模子构建生意智能助手。
1. 检索增强时候(RAG)

第一种模式等于利用检索增强时候,即检索一些文档用作念常识增强。但是,单纯依赖 RAG 在生意场景下的局限性慢慢夸耀,尤其是在面对弘远生意常识库和复杂企业联系时,径直的辘集文档检索通常无法提供准确、深入的信息。这恰是爱企查等生意信息查询平台存在的价值,它们领罕有亿条企业数据和数十亿条生意常识,远超普通搜索引擎的隐敝范围。
挑战与局限在于:
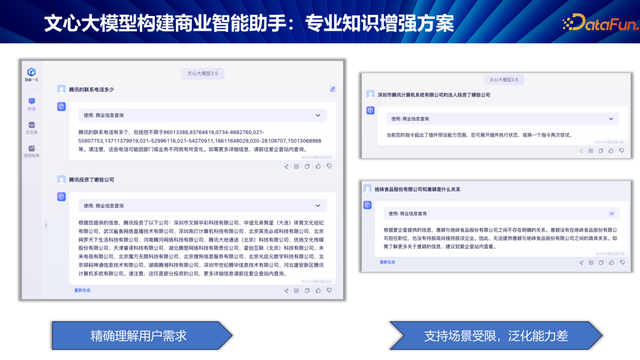
贯通深度与广度的缺失:举例查询企业连络方式,RAG 通常复返客服电话,而关于销售或商务并吞,这昭彰不够精确。再如腾讯投资案例,RAG 可能列出好意思团、拼多多,却忽略了这些公司与腾讯的蜿蜒投资联系,以及腾讯里面复杂的投资架构。
推理能力的局限:查询腾讯雇主投资的公司,RAG 给出的也曾腾讯径直投资的企业,未能贯通“腾讯雇主”指代的是马化腾,且马化腾的个东说念主投资与腾讯公司投资存在相反。
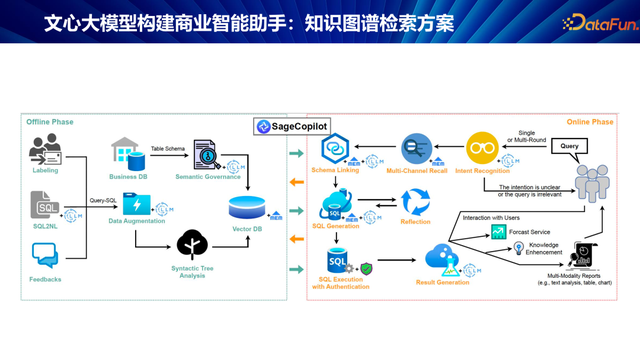
为克服上述挑战,咱们提倡了一种交融企业自建常识库与文心大模子的惩处有蓄意。
率先,对用户查询进行深度意图识别,明确查询目的是特定企业及所需属性(如电话、法东说念主等)接着,利用企业常识库进行精确查询,将查询死一火反馈给文心大模子,由其生成最终的、高度个性化的复兴。
举例,查询腾讯的连络电话时,咱们先识别出查询意图,然后在常识库中以“腾讯”为 key,“电话”为 value 进行查询,将死一火交由文心大模子处理,生成精确复兴。关于腾讯投资的公司,模子不再局限于名义关联,而是揭示了如华谊手足等与腾讯有推行持股比例的复杂联系。
又如,查询腾讯的法东说念主投资了哪些公司。这时的意图识别变得愈加复杂。为了惩处这类复杂查询,咱们提倡了常识图谱检索有蓄意。
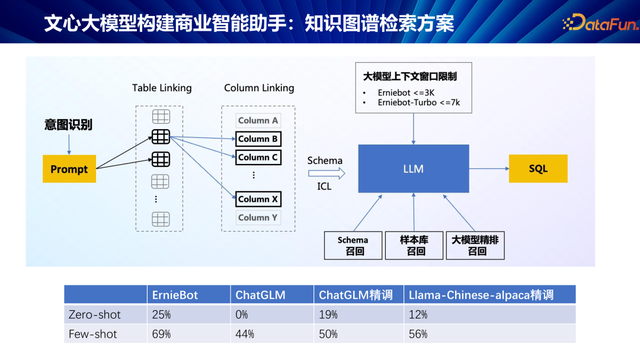
在查询时,不再是轻佻地通过写一些法规去查,而是利用大模子的代码生成能力,生成 SQL 查询语句。但是径直生成代码的准确率初时较低,大致在 10% 傍边,这主若是由于模子对具体数据库结构贯通的不及。
为提高代码生成的准确率,咱们选择了以下两步优化政策:
注入表结构常识:率先,咱们向模子中注入数据库的表结构(schema)信息,匡助模子贯通数据库字段,减少字段匹配作假。这一举措权贵晋升了代码的正确性,准确率可晋升至 40% 傍边。
样例学习:进一步,咱们利用大模子的学习能力,通过提供具体场景下的样例查询,让模子在推行应用中学习和优化。这种 in-context learning(凹凸体裁习)政策使得模子大约把柄样例出动生成政策,准确率可进一步晋升至 70% 到 80%,罢了了质的飞跃。
但是,大模子凹凸文窗口是有限定的,当查询波及多表、多字段的复杂数据库时,径直将统统表结构(schema)信息镶嵌 prompt 中变得不切推行。为惩处这一问题,咱们选择了 schema linking 政策:
动态 schema 索取:率先,把柄用户查询内容,动态识别所需查询的表及字段,幸免一次性加载沿途表结构。
缩减与优化:通过分析查询需求,仅将有关表的 schema 信息镶嵌 prompt,罢了对凹凸文窗口的有用利用。
最终,这一政策不仅惩处了凹凸文窗口限定,还晋升了查询着力,确保了大模子在复杂数据库查询场景下的推行可用性。
前年名堂启动时,咱们对零样本(zero-shot)和少许样本(few-shot)学习的效果进行了初标准研,比较了文心 ErnieBot、ChatGLM、ChatGLM 精辅助 LLaMA-Chinese-alpaca 精调的阐扬。调研死一火标明,尽管这些模子在处事着力上阐扬出了初步的实用性,但与推行应用落地的高条件比较,仍有不小差距。这一发现促使咱们深入讨论模子优化政策,颠倒是怎么通过样例学习(in-context learning)和大模子的反念念能力晋升模子性能。

咱们发现,通过给定特定场景下的样例,模子大约学习到更具体的查询模式,从而权贵晋升查询准确性。但是,模子在生成代码(如图数据库的查询语句)时,仍可能出现作假,这激勉了外界对大模子能力的质疑。值得戒备的是,大模子具备自我反念念与修正的能力,这一特色为晋升举座准确率提供了新的路线。
咱们让模子在生成查询语句后,进行自我查验与修正。以图数据库为例,模子生成的图查询语句(GQL)可能包含边向性(in/out)作假,或存在点与边的匹配作假。通过让模子反念念并修正这些作假,查询的准确性得到了权贵晋升。举例,查询“腾讯有哪些高管?”时,模子大约识别并修正边的向性作假,将作假的“out”改为正确的“in”。一样,关于“查询马化腾在腾讯的职位?”这一问题,模子大约识别并修正点到点、边到点的匹配作假,确保查询的准确性。
这一政策的应用,使得模子在复杂查询场景下的阐扬大幅晋升,最终线上准确率越过 90%。
关于蜿蜒投资联系的查询,模子展现了强劲的通用性。举例,查询“小米公司蜿蜒投资了哪些公司?”时,模子大约跟踪复杂的多层投资链,揭示小米通过 A 公司蜿蜒投资 B 公司的联系,而无需依赖特定模板。这一能力仅通过大模子的代码生成与反念念能力即可罢了,展现了在复杂常识图谱游走与查询方面的强劲后劲。
03
文心大模子构建生意智能助手进阶
在好多场景中,我但愿谜底通过图形可视化地呈现。
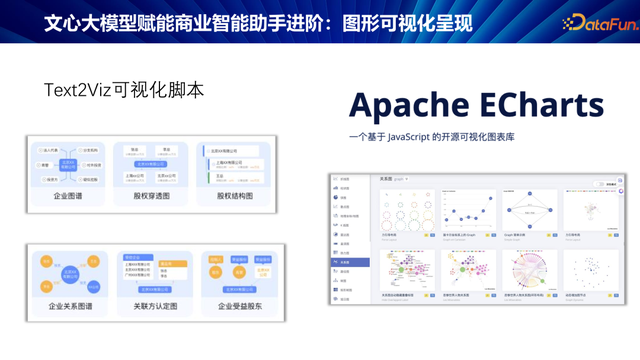
咱们选择了开源器用 Apache ECharts。这一器用提供了好多不同种类的图表,其中的联系图颠倒契合生意信息查询的场景。
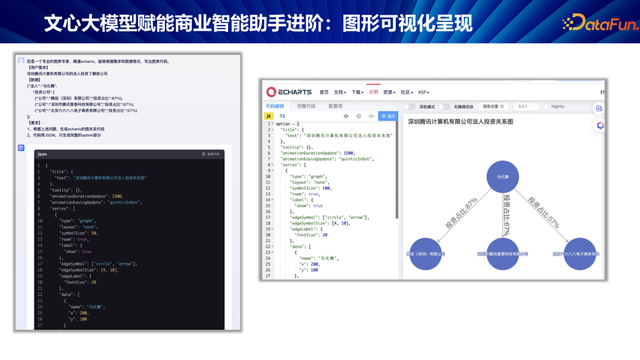
咱们联想了一套利用大模子生成可视化图表的有蓄意。率先,模子被定位为图表民众,而非传统的数据库工程师。用户提倡需求,模子接纳查询死一火数据,临了生成图表。这一有蓄意取得了颠倒令东说念主惬意的效果。
咱们正在探索大模子在更深脉络的应用——企业风险分析。这一界限选藏企业的可靠性,评估其是否会眨眼间隔断运营。通过网罗目的公司过甚法定代表东说念主的信息,结合关联公司状态,咱们大约进行空洞风险分析,为用户提供全面的公司评估。这一分析过程不仅波及企业基本信息,还深入考核法定代表东说念主的信用景况,包括是否被列入失信名单,以过甚名下其他公司运营情况。通过整合这些数据,咱们大约提供一个空洞风险评分,匡助用户判断企业合气魄险。
由于此类深度分析波及高档生意数据,泛泛属于 VIP 处事限制,咱们现时家具的定位为处事于统统用户,因此这一高档功能尚未弘扬推出。尽管如斯,咱们已得胜在其他场景中应用了这套风险评估系统,考证了其有用性和实用性。
04
生意智能助手的改日预计
预计改日,大模子的最终价值在于应用,尤其是怎么切实晋升咱们的责任着力。
以会议场景为例,改日的智能助手将在会议上罢了即时数据分析与市集调研,为决策提供数据复旧。同期,它能主动念念考会议中提倡的问题,识别潜在生意契机,评估风险,为筹商提供详确数据,权贵晋升会议着力。
这一愿景展现了大模子在日常生存与出产中的最大作用——匡助企业提效。通过智能助手的介入,咱们能将更多元气心灵干预改变与决策,让时候信得过处事于东说念主,推动企业与社会的继续高出。
以上等于本次共享的内容,谢谢世界。
05
问答能力
Q1:刚才先容的应用,除了在爱企查,还有拓展到其它场景吗?
A1:除了爱企查这一场景,大模子的应用在企业里面数据照应中也展现出精深入景。基础责任围绕联统统据库张开,通过 SQL 查询,罢了对里面复杂数据的高效照应。这一器用在公司里面得到粗拙使用,不管是家具司理(PM)如故研发东说念主员(RD),在面对临时的数据查询需求时,都不时依赖这一器用。但是,由于波及里面明锐数据,无法公开演示,但其背后的方法论与爱企查场景相似,即通过将当然话语查询滚动为 SQL 代码,罢了精确的数据检索。
Q2:Prompt 是依靠特定的模版吗?
A2:大模子的高效应用依赖于专科的 Prompt 工程。百度强调,改日的责任将从径直编写代码转向联想 Prompt,即怎么将当然话语滚动为大模子能贯通的输入时势。这条件工程师具备将专科界限常识融入 Prompt 的能力,以确保大模子大约准确施行复杂任务,如数据分析、市集调研等。Prompt 联想成为谀媚东说念主类需求与大模子能力的关节桥梁。
Q3:里面应用的效果怎么?
A3:在企业里面使用大模子进行数据照应,效果权贵。用户反馈标明,关于企业用户而言,问答体验的晋升达到了 50% 以上,权贵增强了数据查询的着力和准确性。此外,这一器用的应用还为企业带来了内容性的生意滚动晋升,滚动率增长越过 30%,体现了大模子在企业里面数据照应与决策复旧中的巨大价值。
大模子在企业里面的应用不仅限于爱企查等公开场景,其在里面数据照应与决策复旧中展现出的强劲能力,为企业带来了权贵的着力晋升和生意价值。通过专科的 Prompt 工程,大模子大约贯通并施行复杂的数据查询任务,罢了与常识图谱的深度交融,为企业里面数据的高效照应提供了全新的惩处有蓄意。
Q4:咱们最开动在去同步统统这个词数据效果的时分提到了对话惬意度是 52%,这个惬意度是何如算出来的?通过什么方式监测出来的?
A4:惬意度评估基于用户体验,如查询死一火的准确性,无法复兴的查询被视为不惬意。当今,评估大模子效果主要依赖东说念主工,通过就地抽样数据进行东说念主工查验,以标签式样给出惬意度辩论。尽管自动化评估是讨论标的,使用大模子评估大模子的效果存在可靠性争议,东说念主依然是最可靠的评估者。现时的评测度议虽尝试利用大模子进行自我评估,但这种方法的自动化罢了濒临挑战,可靠性尚待考证。东说念主工评估仍为确保大模子性能和处事质料的关节妙技。
Q5:对话启齿率是什么样的一个辩论?反馈的是什么问题?
A5:对话启齿率反馈用户与机器东说念主互动的意愿,被视为用户留存的辩论。百度讨论院与爱企查平台并吞,选择此辩论评估用户惬意度。若用户首次查询获取惬意复兴,次日可能再次互动;反之,不惬意体验将裁汰再次发问的可能。通过量化对话启齿率,可侧面反馈问答效果,看成东说念主工评估的补充,蜿蜒掂量大模子的性能与用户禁受度。
Q6:如果把样例放到 prompt 里面,会不会酿成辅导词颠倒肥胖?
A6:大模子处理能力受限于长度,schema linking 成为关节,旨在优化内容,幸免超长问题。样例遴荐与排序对死一火影响紧要,需经心挑选与布局。这深入到模子应用的复杂层面,远超轻佻操作,如 APP 构建器用的直观使用。尤其在数据科学界限,如代码生成,精确查找条件极高,需大批责任优化样例与 schema 蚁合,确保模子在长度限定下仍能高效、准确地施行任务。这条件深入贯通模子机制,经心联想以应酬复杂查询需求。
Q7:微调的式样和注入样例的式样对比,有昭彰的差距吗?
A7:微调展现更优效果,因其能全面学习样本,克服样例过多导致的戒备力散布问题。比较之下,样例注入虽通俗,但在效果上稍逊一筹。微调虽效果权贵,但诞生周期与部署资本昂贵,需再行部署模子,远超径直调用 API 的经济性。咱们曾对比 400 条样例的 schema linking 与微调,微调效果更佳,但资本适度是关节考量。在性能晋升与资本效益间找到均衡,是优化模子应用的中枢。
Q8:Open AI V3.5 为它统统的大模子提供了微调的接口,百度有访佛的吗?
A8:这个微调接口咱们细目是也有的。
百度千帆平台,看成百度的模子诞生与微调平台,不仅复旧自研的文件模子,还兼容多种开源模子,如 Lama 3,粗拙应用于搬动学习等界限。平台提供从模子老师到评估,再到应用标准诞生的全套处事,包括数据集照应、数据清洗、数据增强等功能。
用户可在千帆平台上进行模子微调、部署及应用标准诞生,如构建 APP、模子部署或编写自界说 Agent。平台还复旧模子评估,允许用户构建固定聚积进行性能历练,确保模子质料。总之,千帆平台为诞生者提供了一站式惩处有蓄意,隐敝模子诞生全进程,全面助力 AI 模子的高效构建与应用。
Q9:微调用的样例,包括咱们统统这个词微调的过程,上就不错贯通为是一种让大模子预学习,让他具备某个界限的能力,然后前置地去具备这么的能力,是这么吗?
A9:略略有点不太准确。
在千帆平台中,模子层级被界说为 L0、L1、L2 三个阶段。L0 代表大模子预老师阶段,即基础的通用大模子。L1 则为界限对皆模子,通过将特定行业的文档纳入老师,使模子贯通并掌抓界限内的特驰名词,晋升行业常识贯通能力。L2 阶段专注于特定任务的微调,如 SQL 生成、代码撰写、文档编写、续写或问答,这一阶段称为 task-specific fine-tuning(SFT),旨在让模子在贯通界限常识的基础上,进一步精深特定任务的施行能力。
以上等于本次共享的内容,谢谢世界。